Aligned bundling support in LLVM
This document describes the proposal to add aligned instruction bundle support (in short - "bundling") in LLVM and its implementation in the MC module.
Specification
For the purpose of supporting the Software Fault Isolation (SFI) mechanisms required by Native Client, the following directives are added to the LLVM assembler:
.bundle_align_mode <num>
.bundle_lock <option>
.bundle_unlock
With the following semantics:
When aligned instruction bundle mode ("bundling" in short) is enabled
(.bundle_align_mode was encountered with an argument > 0, which is the
power of 2 to which the bundle size is equal), single instructions and groups of
instructions between .bundle_lock and .bundle_unlock directives cannot cross
a bundle boundary.
Furthermore, the .bundle_lock directive supports the align_to_end option,
which means that the group has to end at a bundle boundary.
For example, consider the following:
.bundle_align_mode 4
mov1
mov2
mov3
Assuming that each of the mov instructions is 7 bytes long and mov1 is
aligned to a 16-byte boundary, two bytes of NOP padding will be inserted between
mov2 and mov3 to make sure that mov3 does not cross a 16-byte bundle
boundary.
A slightly modified example:
.bundle_align_mode 4
mov1
.bundle_lock
mov2
mov3
.bundle_unlock
Here, since the bundle-locked sequence mov2 mov3 cannot cross a bundle
boundary, 9 bytes of NOP padding will be inserted between mov1 and mov2.
An example to demonstrate the align_to_end option:
.bundle_align_mode 4
mov1
mov2
.bundle_lock align_to_end
mov3
mov4
.bundle_unlock
Normally, only two bytes of NOP padding would be required between mov2 and
mov3 to ensure that bundle-locked sequence does not cross a bundle boundary.
However, since align_to_end was provided, an additional two bytes of NOP
padding will be inserted so that the sequence ends at a boundary.
For information on how this ability is used for software fault isolation by Native Client, see the following resources:
- http://src.chromium.org/viewvc/native_client/data/site/NaCl_SFI.pdf [PDF link]
- http://www.chromium.org/nativeclient/reference/arm-overview#TOC-The-Native-Client-Solution:-Bundles-
- Other papers listed at http://www.chromium.org/nativeclient/reference/research-papers
Implementation in LLVM MC
As proposed, bundling is a feature of the assembler. Therefore, it is implemented in the MC module of LLVM. Specifically, the following parts are affected:
- The assembler parser is modified to parse the new directives and emit appropriate commands to streamers.
- The assembly streamer (used for printing out disassembly) is modified to emit textual directives back from streamer commands.
- The object streamers are modified to act upon the bundling commands
to affect the assembly process.
- Note: at this point support has only been added to the ELF object streamer. This is done to answer the immediate needs of NaCl and to reduce the complexity of the initial patch. At a later point, bundling support can also be added to the MachO and COFF streamers, if someone is interested.
- The main assembler logic is modified to support bundling.
The following description will focus on the path: Text assembly -> ELF object streamer -> Assembly -> Object file emission. This path can be roughly divided to three stages:
- Parse bundling directives and emit a sequence of sections
(
MCSectionData) and fragments (MCFragmentderivatives) that represent the input. - Perform layout of the fragments to be valid w.r.t. relaxation and bundling.
- Write the output object.
Parsing and emitting sections and fragments
In order to implement bundling, we use the existing assembly parsing facilities in MC, adding support for the new directives. The existing section and fragment abstractions are used, with some flags added to keep the state of the bundling directives encountered. Specifically:
- A
BundleAlignSizefield is added toMCAssembler. When the.bundle_align_modedirective is parsed, this field is populated with the bundle alignment size (2 to the power of the argument of.bundle_align_mode). Setting this field is currently allowed once per assembly file. Subsequent.bundle_align_modedirectives will be rejected as errors. - The following state fields are added to MCSectionData and managed by
the code parsing
.bundle_lockand.bundle_unlock:BundleLockState: keeps track of whether the currently parsed code is in a bundle-locked group (between.bundle_lockand.bundle_unlockdirectives) and whether the group has to be aligned to bundle end.BundleGroupBeforeFirstInst: keeps track of whether the next instruction parsed will be the first in a bundle-locked group.- Turned on when
.bundle_lockis encountered - Turned off when an instruction is emitted in the streamer
- Turned on when
When bundling mode is turned on in the assembler (BundleAlignSize > 0), the
following rules apply to emitting fragments:
- All instructions are emitted into separate fragments (either data or instruction fragments, depending on whether they are candidates for relaxation). This is essential because each instruction may potentially need to be padded to obey bundling rules when layout is performed (details below). Bundling does not apply to non-instructions like data, alignment directives, etc.
- Instructions in bundle-locked groups get emitted into the same data
fragment, since they are all part of the same group which has to be
moved and padded together.
- To make this possible, all potentially relaxable instructions inside bundle-locked groups are relaxed before emission, so that they won't need relaxation in the future.
- While in theory the above means the code can become larger than necessary, in practice instructions actually requiring relaxation won't usually appear in bundle-locked groups, so the practical cost is very low. The gain is a significant simplification of the implementation.
Laying out fragments
Bundling blends well into the existing layout mechanism in the MC assembler, since its effects are somewhat similar to relaxation. Some fragments may need to grow due to padding, which may require re-layout of subsequent fragments and recomputation of fixups. Therefore, the MC assembler employs an iterative layout algorithm. The following diagram will help explain the layout of fragments w.r.t. bundling:
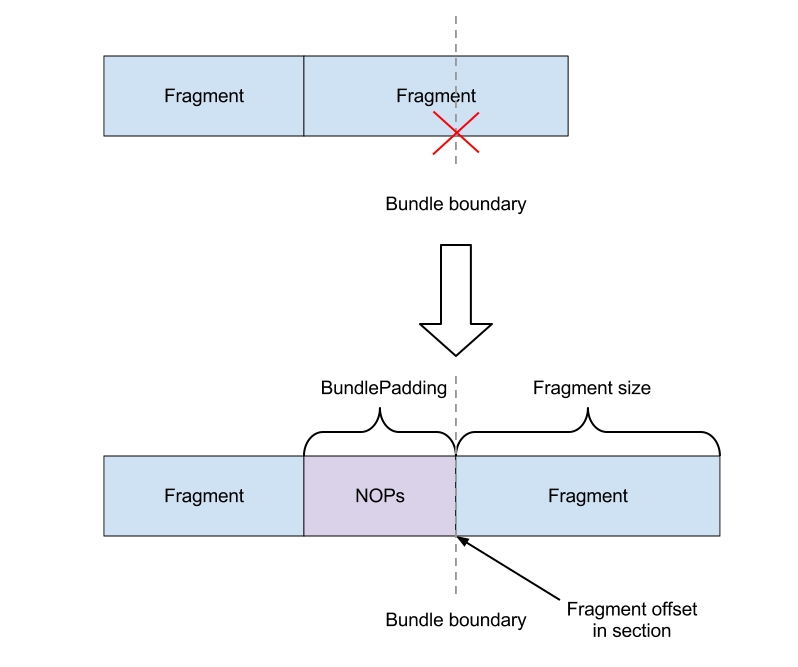
- When layout on a fragment is performed, the fragment's offset and size are computed.
- The following steps apply only if:
- Bundling is enabled
- The fragment contains instructions (we don't pad data and
alignment fragments)
- For this purpose, a boolean predicate
hasInstructionsis added toMCFragment
- For this purpose, a boolean predicate
- If it's determined that the fragment will cross a bundle boundary,
padding is required.
- The required amount of padding is computed and stored in the
BundlePuddingfield of the fragment. This field is restricted touint8_t, in order to save space in the mainstream case (bundling disabled). In practice, fragments of larger size will not be encountered (bundling is done at most on small groups of a few instructions). - The fragment offset is set to point after the padding, at the
start of the actual fragment. This way the following invariant
still holds:
fragment offset + fragment size = offset of next fragment
- The required amount of padding is computed and stored in the
- Padding is also required if the
align_to_endoption is provided to a bundle-locked group.
Note that since we create a single data fragment for a bundle-locked group, the above applies to such groups as well as single instructions.
Writing fragments to the object file
Note: the write target of the assembler is abstracted into a stream object, which can also write into memory. "Object file" here implies this stream.
In the last step, the assembler writes the list of fragments into sections
according to their layout order. In this step, the BundlePadding field created
during layout is used to add NOP padding (by calling writeNopData on the
target-specific assembler backend) of appropriate size before fragments that
require it.
Performance impacts
It's interesting to study the performance impact of adding the bundling feature on MC's assembler normal operation (without actual bundling directives).
Memory consumption of fragment objects
Amount of bytes needed for the various MCFragment objects on x86-64:
| Fragment type | Without bundling | With bundling |
| `MCFragment` | ` 64` | ` 64` |
| `MCRelaxableFragment` | ` 320` | ` 320` |
| `MCDataFragment` | ` 240` | ` 240` |
Explanation: the single-byte BundlePadding field in MCEncodedFragment was
placed in space reserved for alignment earlier. The same was done for the
boolean HasInstructions in MCDataFragment.
Assembler runtime
llvm-mc was run on a large assembly file (produced by compiling gcc 3.5 into a
single assembly file) as follows:
sudo nice -n -20 perf stat -r 10 llvm-mc -filetype=obj gcc.s -o gcc.o
There were no noticeable difference in the runtime of llvm-mc with and without
the bundling patch.
Alternative implementation
Bundling is similar to relaxation in many aspects which simplifies the implementation. While the performance impact of bundling is negligible as shown, the interaction of these two mechanisms can have a negative effect on memory consumption. When bundling is used, most instructions need to be put in their own fragment. That's because before we have decided the sizes of jumps, we don’t know the relative positions of other instructions, as we might need to insert bundle padding NOPs between them. The only exception are bundle-locked superinstruction sequences which can be stored in a single fragment.
Since there's a memory overhead for storing a fragment, the use of bundling with relaxation significantly increases memory overhead. When translating pexe, pnacl-llc uses K * nexe size memory. The experimental results show that the value of K is ~17 with the fixed cost of ~50MB. Given that, with the maximum pexe size limited currently to 64MB, pnacl-llc would need over 1.1GB of address space which is significantly more than 768MB that will be available when pnacl-llc starts using IRT.
Therefore, one way to reduce the memory consumption is to disable jump relaxation. In that case, we know that size of all instructions from the beginning and we can write the bundle padding NOPs directly into the fragments while emitting the instructions, thus reducing the number of fragments needed.
Emitting instructions
We have implemented the alternative bundle padding scheme in LLVM MC. Currently, this implementation is only being used when the -mc-relax-all flag is used. The large bulk of implementation is in the MCELFStreamer::mergeFragment method. We reuse the existing code and emit instructions into their own fragment. We also reuse the existing logic for calculating bundle boundaries and necessary bundle padding. However, when the jump relaxation is disabled, instead of adding each fragment into the list of fragments held by MCSectionData, we merge it with the current fragment.