Disk Cache 3.0
Introduction
This version of the disk cache is an evolution of the previous design, so some familiarity with the previous design (implemented in versions 1 and 2) is recommended. Functionality specific to the new version is implemented by files located under src/net/disk_cache/v3.
Requirements
From the implementation of version 2 (file format 2.1, V2 from this point on), in no particular order:
Survive system level crashes
The design of V2 assumes that system level-crashes are rare enough to justify throwing away everything when corruption caused by a system-level crash happens. That assumption turned out to be wrong.
Allow storing significantly more entries for the same total disk space
One characteristic of Chrome’s disk cache is that it keeps track of entries’ reuse. It even keeps track of entries for some time after a given entry is evicted from the cache, which allows it to correctly identify important content. The new design should allow keeping track of a lot of entries (most of them already evicted) without having to scale the space used as if all entries were present.
Allow growing the main index
There are multiple users of the disk cache, some of which require very little disk space. The cache should be able to start with a small footprint and grow by itself as needed.
Allow memory-only access time to determine a Hit or Miss
The cache should minimize the number of disk operations required to identify if an entry is stored or not. It may be too expensive to do that all the time (think about the memory footprint required to handle collisions with half a million entries), but the probability of requiring a disk access should be much lower than what it is today (if V2 were scaled to the same number of entries).
Keep disk synchronization to a minimum
Disk synchronization (for lack of a better name) refers to actions that attempt to synchronize, snapshot or flush the current state of the cache so that we know everything is in a consistent state. This is bad because there is no real guarantee anywhere that a file flush will actually write to the disk (the OS usually lies to the application, and the disk usually lies to the OS), and flush operations are basically synchronous operations that induce delays and lack of responsiveness.
Another important characteristic to preserve is minimal synchronization at shutdown, and almost zero cost to recover from user level crashes.
Disk space / memory use
This is not really a requirement, but the use of disk and memory is an important consideration.
Detailed Design
Memory Mapped files
The cache continues using memory mapped files, but to be Linux friendly, the mapped section will expand the whole file, so parts that are accessed through regular IO are stored on a dedicated file. That means that the bitmap of a block file is separated from the bulk of the file.
Decent memory mapped files behavior is still considered a requirement of the backend, and a platform where memory mapped files is not available or underperforms should consider one of the alternative implementations.
Batching
As implied by the previous section, the cache will not attempt to batch operations to a restricted period of time in an effort to do some synchronization between the backup files and the normal files. Operations will continue as needed (insertions, deletions, evictions etc).
Reduced address space
The number of entries stored by the cache will be artificially reduced by the implementation. A typical cache will have 22-bit addresses so it will be limited to about 4 million entries. This seems more than enough for a regular HTTP cache and other current uses of the interface.
However, this limit can be increased in future versions with very little effort. In fact, as stated in section 2.3 the cache will grow as needed, and the initial address space will be much lower than 22 bits. For very small caches the cache will start with a total address space of just 16 bits.
If the cache is performing evictions, there is an extra implied addressing bit by the fact that evicted entries belong to their own independent address space, because they will not be stored alongside alive entries.
Entry hash
An entry is identified by the hash of the key. The purpose of this hash is to quickly locate a key on the index table, so this is a hash-table hash, not a cryptographic hash. The whole hash is available through the cache index, and we’ll use a standard 32 bit hash.
Note that this means that there will be collisions, so the hash doesn’t become the unique identifier of an entry either. In fact, there is no unique identifier as it is possible to store exactly the same key more than once.
UMA data from Chrome Stable channel indicates that the top 0.05% of users have bursts of activity that if sustained would result in about 39000 requests per hour. For the users at the 80 percentile mark, the sustained rate would be about 4800 requests per hour. Assuming a cache that stores about half a million entries when full, and uses a 32 bit hash with uniform distribution, the expected number of collisions in an hour would be about 4.7 for the 99.5 percentile and 0.56 for the 80 percentile. This means that the expected time between collisions would be a little over 12 minutes for the 99.5 percentile and at least 106 minutes for 80% of the users.
The effect of having a collision would be having to read something from disk in order to confirm if the entry is there or not. In other words, a collision goes against requirement 2.4, but requiring one extra disk access every hour is well within reason. In order to completely eliminate collisions, the hash would have to be increased to at least 128 bits (and maybe move away from a standard hash table hashing) which goes against requirement 2.6 by substantially increasing the size of the index and it would actually make keeping track of in-progress deletions much harder.
Data backtrace to the entry
All data stored individually somewhere by the cache should contain a way to validate that it belongs to a given entry. The identifier would be the hash of the key. If the hash matches, it is assumed that everything is fine; if it doesn’t, the conclusion would be that this is a record that belonged to a stale entry that was not correctly detected before.
Index
The whole index is memory mapped, has a header with relevant details about the whole backend, and the bitmap and header are backed up periodically using only regular IO. The actual table is divided in two parts: the main table (stored as “index_tb1”) always grows by a factor of 2, and the overflow or extra table (stored as “index_tb2”) which grows by smaller increments. (See buckets for more details).
Bitmap
Every cell of the hash table has an implied number (the location of the cell). The first cell of the first bucket is cell 0, the next one is number one etc. There is a bitmap that identifies used cells, using regular semantics. The bitmap is stored right after the header, in a file named “index” (backed up by “index_bak”).
Control state
Each cell of the index table can be in one of the following states:
Free - State 0 (bitmap 0)
New - State 1 (bitmap 1). An entry was added recently
Open - State 2 (bitmap 1)
Modified - State 3 (bitmap 1)
Deleted - State 4 (bitmap 0)
Used - State 6 (bitmap 1). A stored entry that has not seen recent activity.
The state is represented by three bits, and state 7 is invalid, while 5 is used temporarily for entries that are invalid while they are fixed. Each time the state changes to something else, the corresponding bit on the bitmap should be adjusted as needed.
Insert transitions
Let’s say that the full state of an entry is determined by [state - bitmap - backup] (see section 3.10 for information about backups).
Inserting an entry requires the following transitions:
\[free - 0 - 0\]
\[new - 1 - 0\]. Pointers and data added.
\[new - 1 - 1\]
\[used - 1 - 1\]
A system crash between 2 and 3 can result in either 1 or 2 being persisted to disk. If it is 1, there’s no information about the new entry anywhere, so in fact the entry was not inserted. If it is 2, the mismatch between the bitmap and the backup (and the fact that the state is “new”) allows detection of the crash impacting this entry, so the actual data should be verified.
A system crash between 3 and 4 may end up in state 3 after restart, and we know that the entry was being inserted. If for some reason the relevant page was not saved to disk, the state could be [free - 0 - 1], in which case we know that something was wrong, but we don’t have the address or has of the entry which was being inserted, so effectively nothing was added to the index. In that case, we may end up with some data pointing back to some hash that doesn’t live in the table, so we can detect the issue if we attempt to use the record.
Remove transitions
Removing an entry requires the following transitions (for example):
\[used - 1 - 1\]
\[deleted - 0 - 1\]
\[deleted - 0 - 0\]. Actual data removed at this point.
\[free - 0 - 0\]. Pointers deleted.
A system crash between 2 and 3 can result in either 1 or 2 being persisted to disk. If it is 2, we know that something is wrong. If it is 1, to prevent the case of an entry pointing to data that was deleted (although the case will be recognized when actually reading the data), the deletion should be postponed until after the backup is performed. Note that deleting and creating again an entry right away is not affected by this pattern because the index can store exactly the same hash right away, on a different table cell. At regular run time it’s easy to know that we are in the process of deleting an entry, while at the same time there’s a replacement in the table.
A system crash between 3 and 4 will either see the entry “deleted”, or “used” with the bitmap mismatching the backup, so the problem will be detected.
Entry
The cache stores enough information to drive evictions and enumeration without having to rebuild the whole list in memory. An entry on the hash table has:
Address (22 bits). Points to the actual entry record.
State (3 bits). See [section 3.6.2](#TOC-Control-state)
Group (3 bits). Up to 8 different groups of entries: reused, deleted etc.
(old Lists).
Reuse (4 bits). Reuse counter for moving entries to a different group.
Hash (18 bits). Enough to recover the whole hash with a big table.
Timestamp (20 bits).
Checksum (2 bits). To verify self consistency of the record.
For a total of 9 bytes.
The limited timestamp deserves a more detailed explanation. There is a running timer of 30 seconds that is the basis of a bunch of measurements on the cache. Stamping each entry with a value from that counter, and keeping 20 bits, provides about one full year of continuous run time before the counter overflows.
The idea of the timestamp is to track the last time an entry is modified so that we can build some form of LRU policy. Ignoring overflow for a second, in order to get a set of entries for eviction all we have to do is keep track of the last timestamp evicted, and walk the table looking for entries on the next set: all entries that have the closest timestamp to the previous one, and on the desired Group. This gives us all entries that were modified on the same 30 seconds interval, with the desired characteristics.
At some point when we are getting close to reach overflow on the timestamp all we have to do is rebase all timestamps on the table. Note that the backend keeps a full resolution time counter, so we just have to track the range of entries stored by the cache. This, of course, limits the range of last-modified entries storable by the cache to about one year, assuming that the browser is never shut down. Keeping an entry alive for that long without accessing it sounds like more than enough for a cache.
The expected pattern is that most entries tracked by the cache will be “deleted” entries. For those entries, the timestamp is not really needed because deletion of evicted entries is not controlled by the timestamp but simply by discarding a bunch of entries that are stored together.
A small cache (say for 256 buckets) needs to store 24 bits of the hash in order to recover the whole value. In that case, the extra 6 bits come from the address field that shrinks to 16 bits, enough to cover 64K entries. The overhead for very small repositories with 1024 entries minimum would be: 10KB for the table, 4KB for the header/bitmap + 4KB for the backup.
Buckets
A bucket is simply a group of 4 entries that share the same high order bits of the hash, plus a few extra bits for book keeping.
For example, a hash table with 1024 cells has 256 buckets where each bucket has 4 entries. In that case, the low order byte of the hash is shared by the four entries inside the bucket, but all entries can have anything on the high order bits of the hash (even the same value).
When the four entries of a bucket are used, the next entry with a matching hash will cause a new bucket to be reserved, and the old bucket will point to the new one. New buckets are used on demand, until the number of extra buckets gets close to the number of buckets on the main table. At that point the table size is doubled, and all extra buckets are assimilated into the new table. Note that the process of doubling the size and remapping entries to cells is very simple and can be performed even while entries are added or removed from the table, which is quite valuable for large tables.
Using the baseline entry described in section 3.6.3, the corresponding bucket will look like:
Entry 1 (9 bytes)
Entry 2 (9 bytes)
Entry 3 (9 bytes)
Entry 4 (9 bytes)
Next bucket (4 bytes, the address of a cell as referenced by the bitmap of
[section 3.6.1](#TOC-Bitmap))
Hash (up to 4 bytes, for buckets outside of the main table)
For a total size of 44 bytes.
Continuing with the example of a 1024-cell table, this is a representation of the buckets:
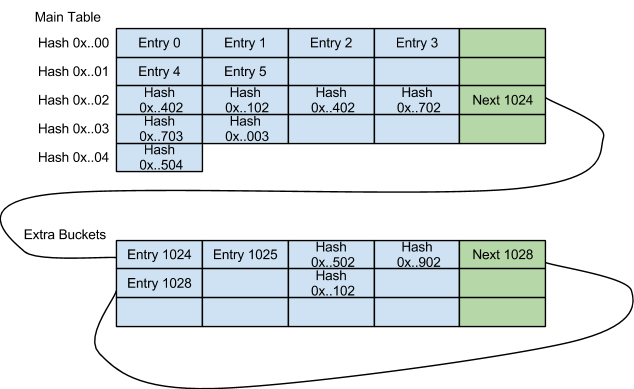
Note that all entries that share the same lower 8 bits belong to the same bucket, and that there can be empty slots in the middle of a bucket. The initial table size would be 256 buckets, so entry 1024 would be the first cell of an extra bucket, not part of the main table.
The presence of chained buckets allows a gradual growth of the table, because new buckets get allocated when needed, as more entries are added to the table. It also allows keeping multiple instances of the same entry in the table, as needed by the system crash correction code.
EntryRecord
A regular entry has (104 bytes in total):
Hash (32 bits). Padded to 64 bits
Reuse count (8 bits)
Refetch count (8 bits)
State (8 bits)
Times (creation, last modified, last access) (64 bits x 3)
Key Length (8 bits)
Flags (32 bits)
Data size (32 bits x 4 streams)
Data address (32 bits x 4)
Data hash (32 bits x 4)
Self hash (32 bits)
Extra padding
Note that the whole key is now part of the first stream, just before user provided data:
Stream 0: owner hash (4 bytes) + key + user data.
Stream 1..3: owner hash (4 bytes) + user data.
A small data hash (fast, not cryptographic) is kept for each data stream, and it allows finding consistency issues when a straight, from start to end pattern is used to write and read the stream.
For an evicted entry the cache keeps (48 bytes in total):
Hash (32 bits)
Reuse count (8 bits)
Refetch count (8 bits)
State (8 bits)
Last access time (64 bits)
Key length (32 bits)
Key hash (160 bits)
Self hash (32 bits)
In this case all the data streams are deleted, and that means that the key itself is not preserved. That’s the reason to rely on a much stronger key hash. Note that there is no harm if a URL is built to collide with another one: the worst that would happen is that the second URL may have better chances of being preserved by the cache, as long as the first URL was already evicted.
Block files
The structure of a block file remains the same. The consistency of the block file is taken care by detecting stales entry at the index layer and following the data records to the block files, while verifying the backtrace hash. The only difference is that now a block file is backed by two actual files: the header + bitmap (a file named “data_xx”) and the actual data (a file named “data_xx_d”).
In terms of number of files, the rankings file is gone and now there is a dedicated file for live entries, and another one for deleted entries. External files are also tracked by a dedicated block file.
As a future improvement, we can consider moving entries to dedicated files once they reach the highly reused group.
External files
External files will be tracked by a block file that basically just have the bitmap of used files and the backtrace data to the owning entry (the hash). The actual number of files per directory is limited to 1024.
Backups
There is a backup file of the index bitmap (+ header), updated using regular, buffered IO at a given interval (every 30 seconds), without any flushing or double-file with replacing.
It is assumed that the operating system will flush the memory mapped sections from time to time, so there is no explicit action to attempt to write the main bitmap to disk. In general, it is expected that memory mapped data will reach disk within the refresh interval of the backup, so that a complete write cycle may take from one to two backup cycles. Note that this doesn’t imply that the memory mapped data write has to be synchronized in any way with the backup cycle.
For example, consider a typical cycle for removing an entry from the index (as explained in section 3.6.2.2):
\[used - 1 - 1\]
\[deleted - 0 - 1\]
\[deleted - 0 - 0\]. Actual data removed at this point.
- [free - 0 - 0]. Pointers deleted.
Step 2 happens at a random place during backup cycle n. Step 3 happens at the start of backup cycle n+1, but the backup data itself will reach disk at some point after that (being buffered by the operating system). Step 4 takes place at the start of backup cycle n+2, so roughly a full cycle after the backup file was saved and the data deleted from the cache.
If the slot is reused for another entry after step 4, ideally the intermediate step (2-3) reaches disk before the slot transitions again to a used state. However, if that doesn’t happen we’ll still be able to detect any problem when we see a mismatched backtrace hash.